
Artificial intelligence is getting more and more traction over the years: from Instagram cat filters to SpaceX launch missions, everything is at least partially dependent on executing calculations instructed by the machine. For tasks that require continuous awareness and complex human knowledge, such as securing your house from intruders, AI seems to be the ideal solution. Sure, you might get a dog, spend several months (or years) training it on who should, and should not, be allowed into your home (intruders), teach it to take appropriate action (bark or bite) and ensure that your dog adapts with newly acquired information (“the guy delivering the mail is likely not an intruder, I see him every day”). AI is not that much different, except that it can be trained faster, doesn’t sleep, doesn’t get distracted and can’t be bribed with dog treats.
At Palmear, we don’t specialize in detecting who enters the house — we monitor when and what lives in the house. The “what” is a number of agricultural pests, the “when” is as early as possible, and the “house” is any plant that suffers from its inhabitants. Since these “houses” usually don’t have windows, our best bet to check what’s going on is through sound.
What are psychoacoustics?
Sound is a pressure wave created by a vibrating object, such as a loudspeaker, a guitar string, or a palm tree being ingested from the inside by an insect. Fig.1 roughly demonstrates how sound waves are emitted and received by the human ear
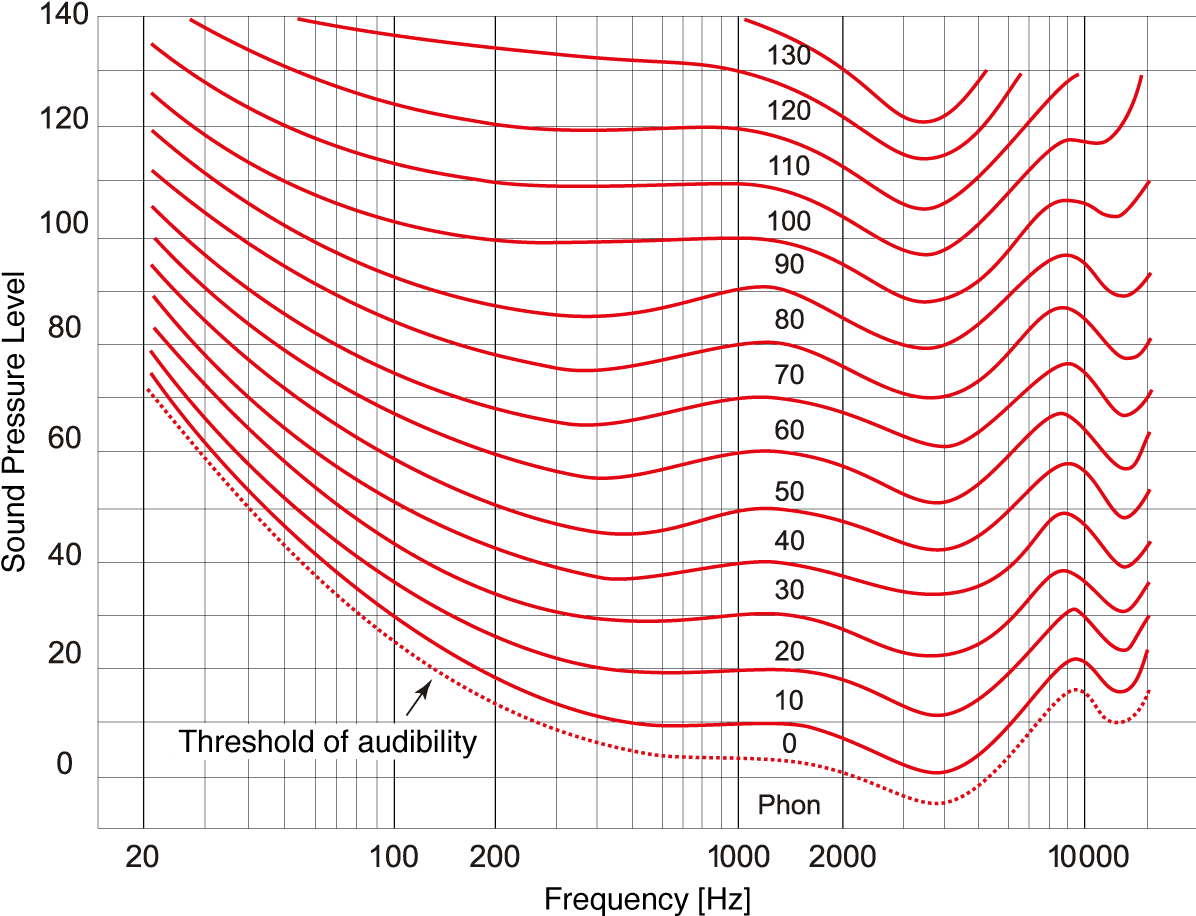
Let’s go back a bit to visual surveillance: a digital image is an organization of pixels in a certain way — basically what you see is very correlated with how the data is really organized. For example, if an orange cat is located in the lower right quadrant of the picture, orange pixels will be placed in the lower right quadrant of the 2D matrix that represents that picture in the digital world. Now, notice the vibrating sinusoidal pattern of the sound in the GIF above: we don’t hear a “wobbly” sound of wave moving back and forth in our ears, but a pure tone. In other words, the manifestation of sound in nature is not how we perceive it by loudness, pitch, roughness and so on. Our hearing system translates it into something we can understand: the “height” of the vibration is associated with loudness, “density” of sound waves with sound pitch and the shape of the sound wave with timbre or tone. Not that intuitive, right? Furthermore, increasing the sound wave power two times won’t be perceived by us as hearing the sound that is two times louder, but in reality, it will be closer to 20–25%. We also don’t hear sounds of different pitch with equal loudness (Fig. 2), so a sound produced by a cricket would be recognized as louder than the equally strong sound of an owl hooting. The models that translate the physical aspect of sound signals to how we perceive them are a part of psychoacoustics — the study of human perception of sound.
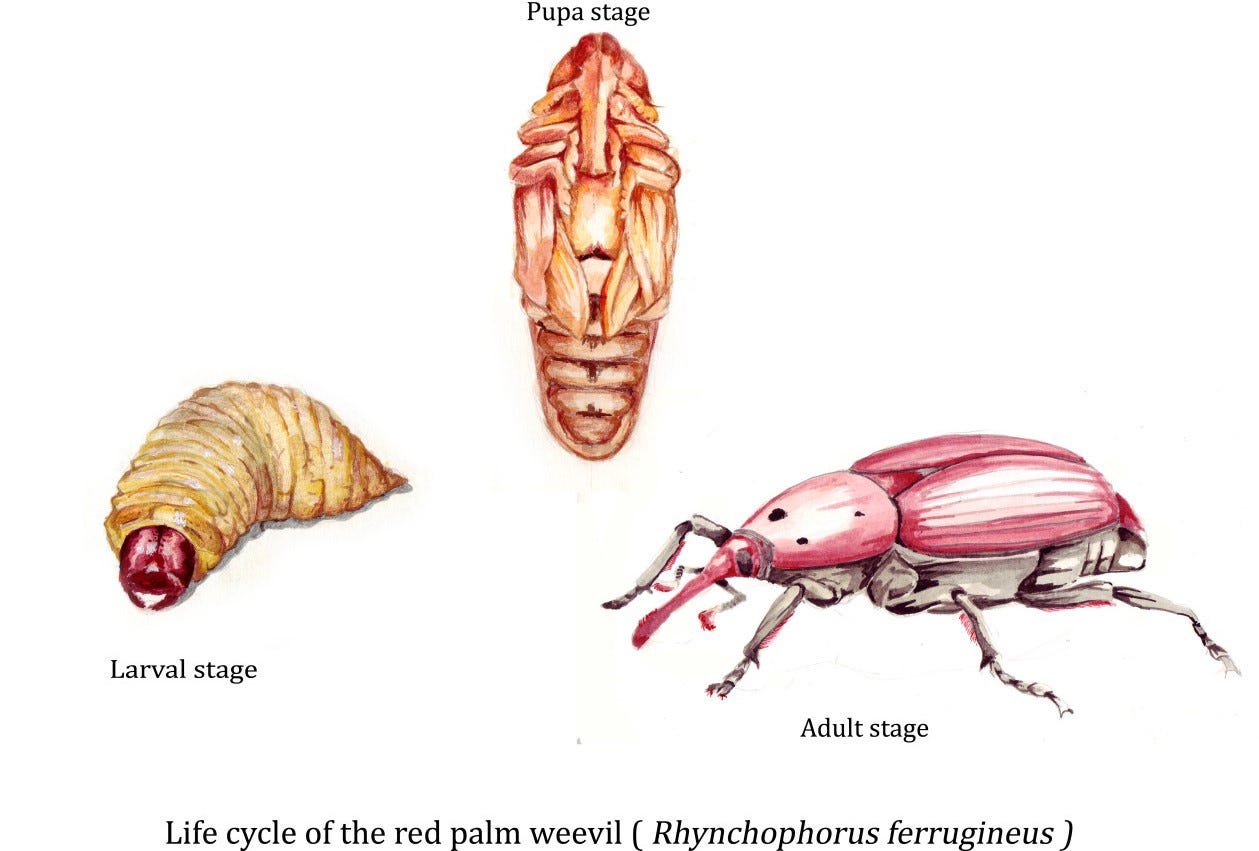
Pests in agriculture: The case of the Red Palm Weevil
There are many agricultural pests in nature threatening agricultural production around the globe, spanning from Japanese beetles to potato bugs. Controlling such issues usually involves the usage of insecticide baits, pesticides or other chemical means, while it can be even too late for plants being severely infested. Monitoring takes place early, during the gestational phases, where pest larvae can nest in various environments. For example, locusts nest in hard soils, while red palm weevil (RPW) larvae usually attack palm trees. This one is particularly savage, as being the single most destructive pest for dozens of palm species globally. For example, around 50% of date palms (that’s 50 million trees!) are at risk of being attacked by the red palm weevil. RPW larvae emit sounds that can (sometimes, if the larva is big enough) be heard by a trained ear from the outside of the tree.
However, there are multiple problems with the trained ear:
– although the human ear is sensitive enough, its owner might mislabel the sound and/or just not hear it well enough,
– it would be almost impossible to make a human systematically listen for these faint sounds in large farm settings,
– acquiring enough people to quickly and accurately assess the infestation levels can be expensive.
With all of the aforementioned taken into account, you might ask: is it possible to make the AI listen for these sounds? Definitely yes!
Psychoacoustic descriptors for AI
For any AI that incorporates machine learning, interesting features would need to be extracted. For example, let’s you’d like to detect if an animal is a cat or a dog, and then you’d extract animal height as one feature to use. Since there are dogs that are smaller than some cats, that one feature would not be enough to distinguish all cats from all dogs, not by a long shot. Then you’d extract some more: animal weight, tail length, ear shape, fur length, color and so on. For dogs smaller than cats, maybe ear shape is significantly different from large cats’ ear shape, and then you’d be able to distinguish even the majority of small dogs from large cats. You’d want to distinguish more precisely and add more features, so you’d add even more features and so on and so on. The process is obviously iterative and pretty intuitive, however humans can’t “juggle” with so many features at once. AI, on the other hand, can do thousands (even more) at the same time.
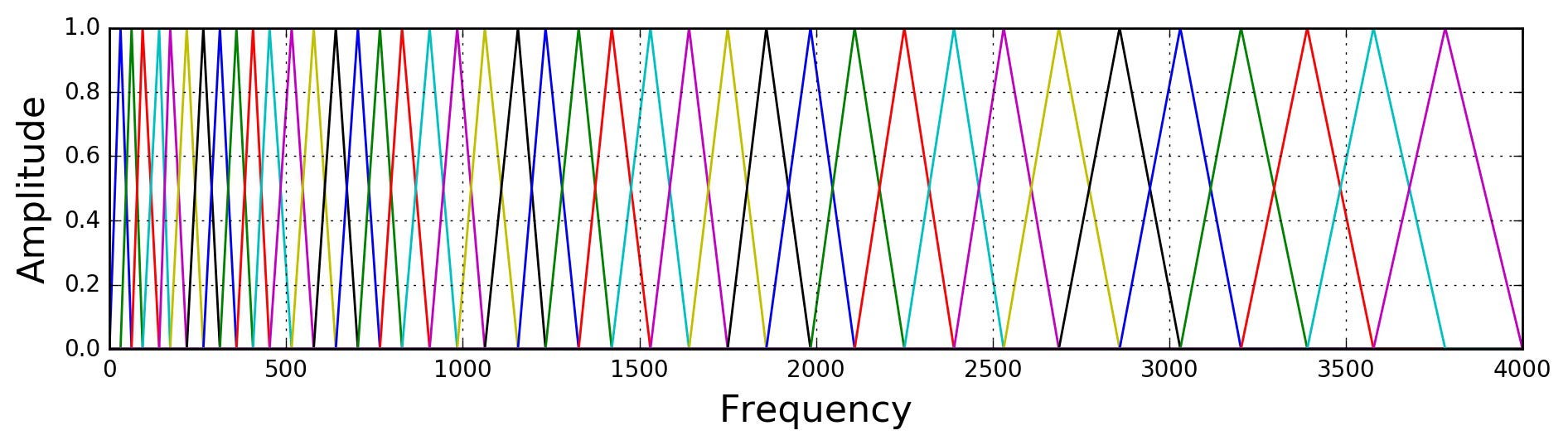
The best features are often those which describe the problem in the most “human” way, since the (rough) goal is to “transfer” our own reasoning into the machine. For example, images contain a 2D matrix of RGB values, which is similar to how we perceive them, so it would be meaningful to have them as features for image classification. Audio is a totally different story: objective features, such as signal amplitude, frequency and phase might be meaningful, but the way we hear is defined through psychoacoustic modeling that incorporates bark scales, large sensitivity to discontinuities and very meager sensitivity to e.g. phase. Fig. 4 gives modeling of the human cochlea excitation through a set of Mel frequency bands.
There are many psychacoustics descriptors which have been proven to work very well with any audio signal, such as mel frequency cepstral coefficients (MFCCs), gammatone cepstral coefficients (GTCCs), tonality, spectral brightness etc. The following section will demonstrate how making an AI (machine learning) model with psychoacoustic features fares in comparison with the model that uses objective audio features.
Results
We have devised our own data collection methodology, designed to collect clean and noise-free sound of agricultural wood boring pests. Many hours of labeled RPW recordings are used for the training procedure. After our models are trained with the relevant data, a testing phase is required to validate that they will work well after being deployed to the farms under monitoring. Results showcased here indicate that the psychoacoustic (“subjective”) features work better than model trained only with objective features: they are more robust in disregarding sounds similar to RPW larvae activity (e.g. sounds of ants walking), exhibit better conformance with what a human expert would render an infestation and have better accuracy in general. The trained AI model is able to define the infestation level after 5 to 10 seconds of monitoring a tree and label it as either as non-infested, suspicious or infested. If any of the latter two cases occur, the tree is flagged and further investigation will be done as soon as possible.
As an example of how psychoacoustic model performs better than the model with objective audio features, we have taken a small subset of our dataset and trained 5 different models on it, first with objective features and then with psychoacoustic features. All features were extracted on an arbitrary small window of 50 ms length. For objective features, we’ve taken the following twelve features: mean, mean of 1st derivative, median, max, min, standard deviation, percentiles (25th, 75th and 95th), standard deviation of frequency spectrum, kurtosis of frequency spectrum and skewness of frequency spectrum. On the other hand, we’ve calculated 12 MFCC values (there are usually 13 MFCCs, but the first one usually gets discarded). The model contained more than 4000 observations, with positive to negative ratio being close to 25:75. For validation, a 10-fold cross-correlation was applied.

Fig. 5 shows the comparative results for 4 different metrics: precision, recall, F1 score and accuracy. It’s quite simple actually: precision is the ratio between correctly predicted positives and total predicted positives (TP / (FP + TP)); recall is the ratio between correctly predicted positives and all positives that should have been predicted(TP / (TP + FN)); F1 score is the weighted average between precision and recall; accuracy is the ratio between correctly predicted observations and all observations (T / (T + P)).
As you can see, psychoacoustic features severely outperform the objective ones, which can especially be seen in their precision and recall scores, and F1 score as a consequence. For example, check the recall values. The SVM classifier with cubic kernel trained with objective features would correctly find only 33.4% positives. That would mean that we would be in danger of wrongly labeling almost 67 out of 100 trees as not being infested, while they would actually contain RPW larvae. Imagine that! On the other hand, the same classifier trained with psychoacoustic features would correctly find 99.5% of all the positives it should have found, meaning not even one infested tree would be rendered clean of RPW.
Feature engineering is a great way to get better results from your model, and making it conceptually closer to human-like sensing can be a very worthwhile way to achieve more precise predictions. Hope you liked it!